自定义数据
词库和字集过滤
Section titled “词库和字集过滤”在「基本」页面的右上方,您可以看到关于系统默认采用的词库的说明。您可以下载该词库,查看其格式并根据您的需要定制,再上传。
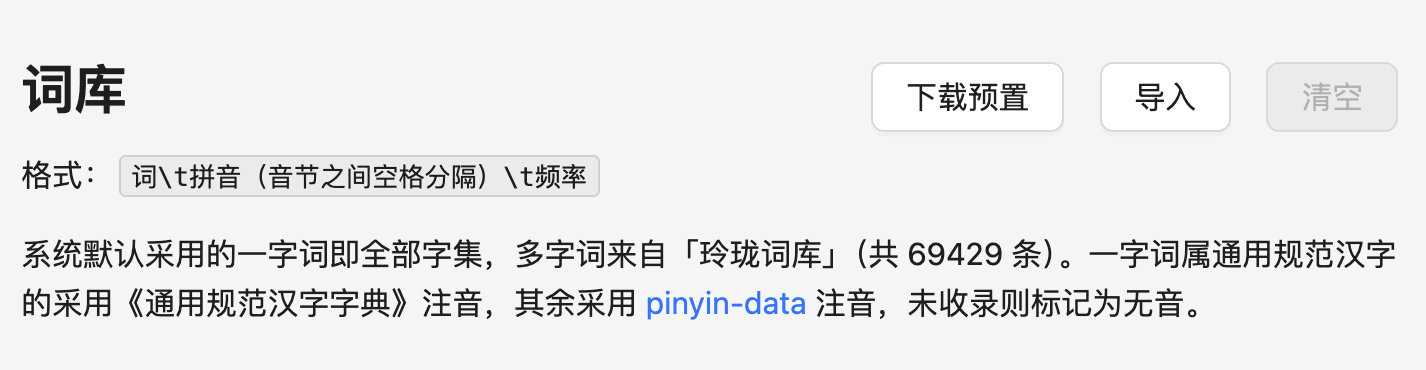 另外,如果您没有太多自定义词库的需求,只是希望限制字集范围,您可以简单地在左下方选择:
另外,如果您没有太多自定义词库的需求,只是希望限制字集范围,您可以简单地在左下方选择:

关于拼音的说明
Section titled “关于拼音的说明”值得注意的是,词库中每一行包括词、拼音、频率,这意味着频率是按照词和拼音共同统计的,例如 了 le5 和 了 liao3 应该有不同的频率。如果您希望自定义频率,需要考虑到这一点。另一方面,如果您制作的方案不包含任何拼音元素(即纯形码),则可以忽略这一点,将频率设为词自身的频率,而拼音字段可以随意填写。
同时,词库的自定义也允许了用户使用普通话以外的语言所对应的拼音,例如古汉语、汉语方言、域外方音。对于普通话来说,默认的注音是带调拼音,如果您不需要声调元素,在导入词库时也可以在拼音字段填写无声调拼音(可以视为一种自定义的语言)。不过,系统默认的拼写运算都是针对(有声调)普通话拼音编写的,在您调整语言时也需要编写新的拼写运算。
字形数据的基本介绍
Section titled “字形数据的基本介绍”数据界面展示了自动拆分所使用的原始数据。
如前所述,在拆分时系统只需要考虑基本部件和复合体两种字形。但是在原始数据中,为了便于维护数据库,存在五种不同的字形:
- 基本部件:和之前的含义相同,即直接使用 SVG 绘制出的部件;
- 衍生部件:在一个部件的基础上,通过增加和减少一些笔画衍生出的部件;
- 拼接部件:在多个部件的基础上,通过拼接得到的部件;
- 复合体:多个部件或复合体按照一定位置关系组合;
- 全等字形:定义它完全等同于另一个字。
这里的关键在于减少工作量。例如,在已经有了「木」基本部件之后,「本」就可以通过加一笔衍生的方式来实现。再比如,像康熙部首、CJK 部首补充等 Unicode 区块的字符常常在 CJK 基本区有完全等价的字符。
为什么每个字有多个字形
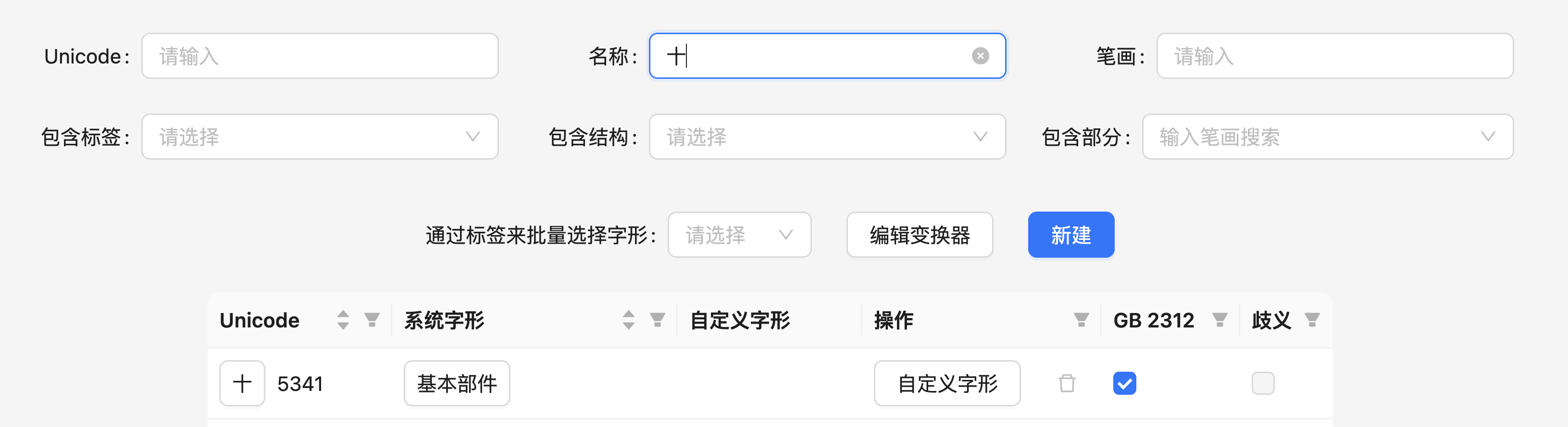
Section titled “为什么每个字有多个字形”此外,对于一个汉字,系统可能会提供它的一个或多个字形。一般来说,每个汉字只有一个字形,例如「十」就只有一个字形,它是一个「基本部件」:
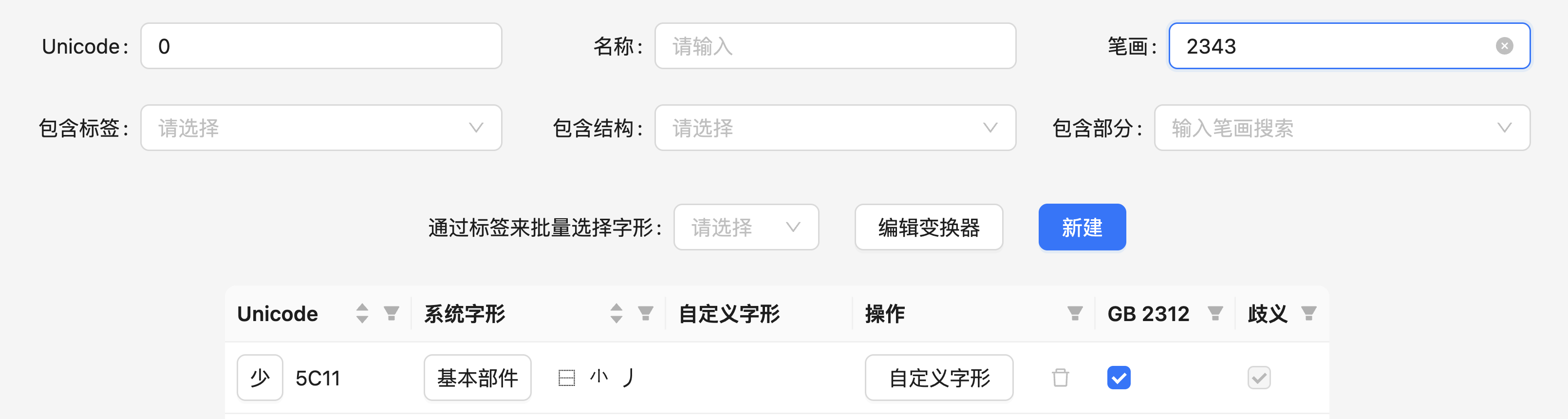
但是,也有可能有多个字形。例如,「少」有一个基本部件的字形,也有一个复合体的字形(看成是上下结构)。
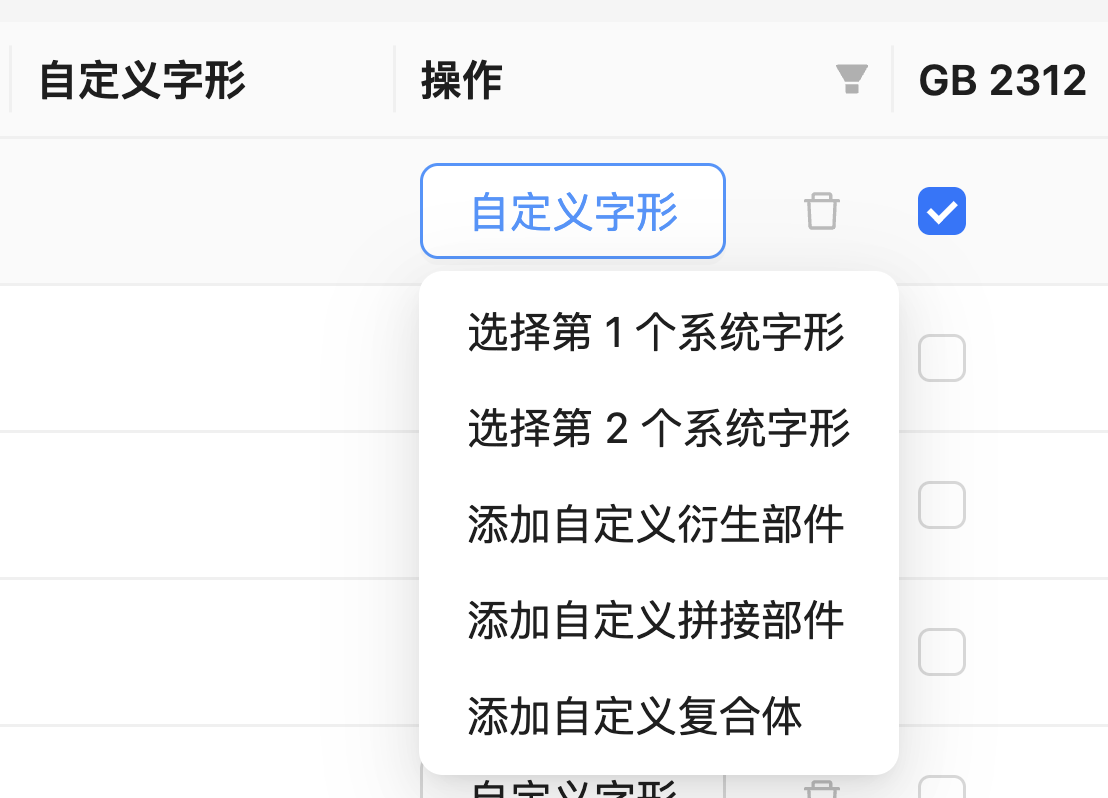
一个字究竟采取哪个字形,在不同的方案之间有一定的灵活空间。例如,一个采取分部取码的方案通常会自己定义哪些字可分、哪些字不可分。因此,方案可以在系统提供的多个内置字形中任意选择一个,也可以自己从头创建一个。自定义的菜单如图所示:
预处理的流程
Section titled “预处理的流程”这样的数据库在用于拆分之前会先经过一个预处理的步骤。其过程分为两步:
- 将衍生部件和拼接部件递归解引用变成基本部件、全等字形递归解引用变成基本部件或者复合体;
- 根据自定义的情况,在多个字形中选取一个;在没有自定义的情况下,默认选取系统字形中的第一个。
理解了这一过程之后,我们现在就可以来自定义字形数据,让它更符合输入方案的需求。
字形数据的自定义
Section titled “字形数据的自定义”选择系统字形中的一个
Section titled “选择系统字形中的一个”前面的几个选项表明可以选择系统中现有的若干个字形中的一个。选择后,该字形会出现在「自定义字形」列中。
自己创建一个
Section titled “自己创建一个”后面的几个选项表明可以自己从头创建一个字形。其含义为:
- 自定义衍生部件:以某个已有的部件为蓝本,增加和减少少量的笔画形成新的部件;
- 自定义拼接部件:把某些部件按一定的空间位置关系拼接起来,但结果仍然看作是一个部件;
- 自定义复合体:把某些部件或复合体按一定的空间位置关系拼接起来,成为一个复合体;
使用变换器来批量自定义字形
Section titled “使用变换器来批量自定义字形”如果希望批量自定义一系列字的字形,则可以使用「变换器」功能。例如,「衔衍衡衙街……」等一系列字中系统默认的分部方式是左中右三分:
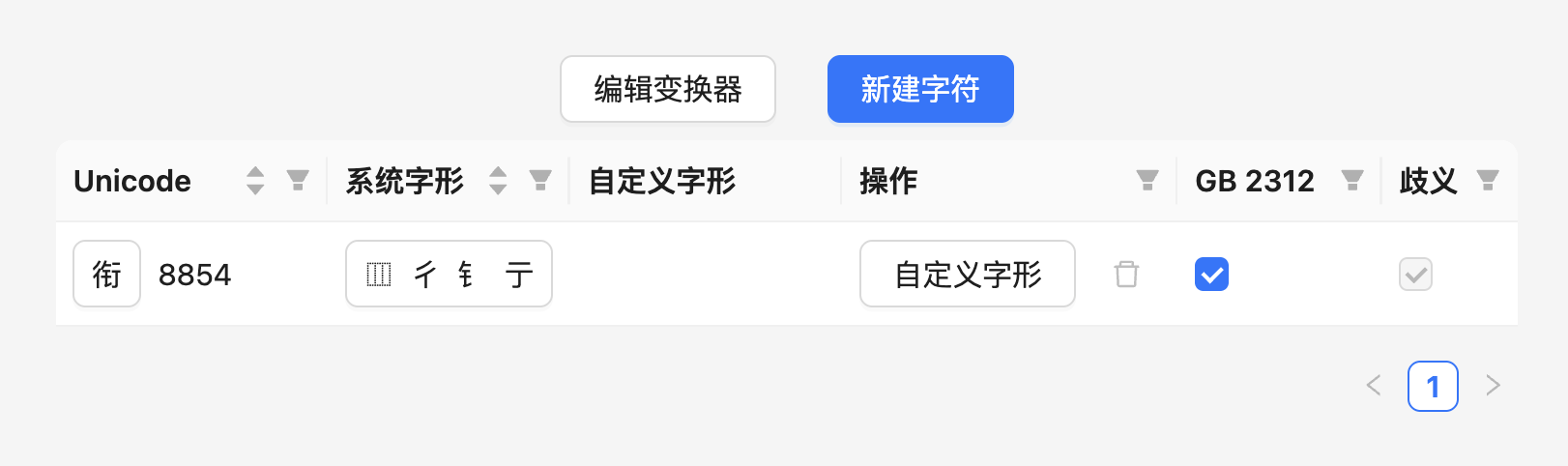 此时如果想拆出「行」字根,就必须对这些字批量自定义。点击「编辑变换器」进入变换器的编辑界面,可以看到系统已经预置了一些常见的变换可能性:
此时如果想拆出「行」字根,就必须对这些字批量自定义。点击「编辑变换器」进入变换器的编辑界面,可以看到系统已经预置了一些常见的变换可能性:
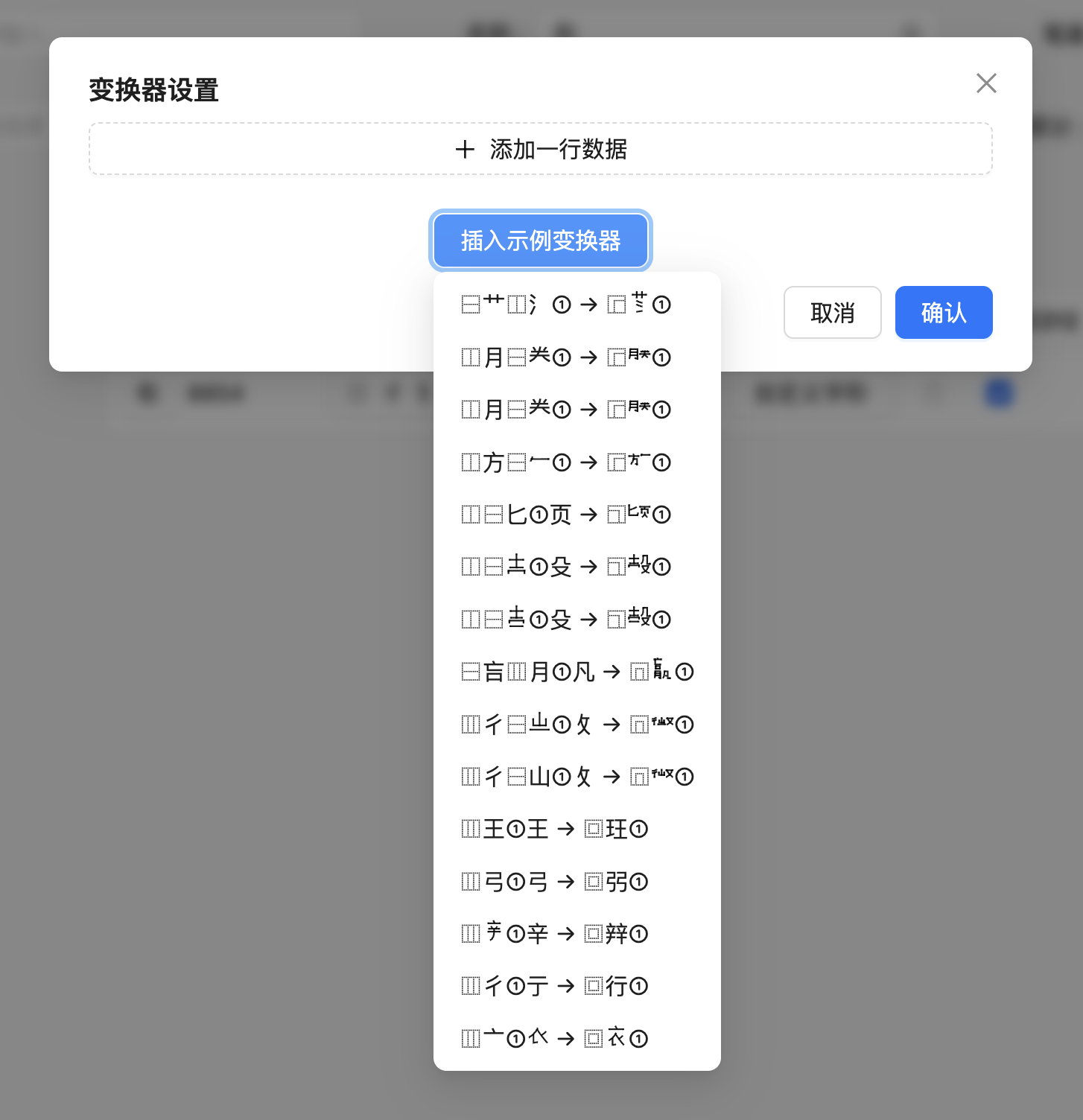 在预置的变换器列表中发现「⿲彳①亍 → ⿴行①」这个条目,点击添加之后,可以看到变换器列表中出现了这一项:
在预置的变换器列表中发现「⿲彳①亍 → ⿴行①」这个条目,点击添加之后,可以看到变换器列表中出现了这一项:
 它的含义为:「寻找数据库中符合左中右(⿲)结构、左部为「彳」、右部为「亍」的字符,并将其中部提取出来作为一个变量。然后,将其字形变换为全包围(⿴)结构、外部为「行」、内部为刚才那个变量的字形。」仿照这个例子,您就可以开始设计自己的变换器了。
它的含义为:「寻找数据库中符合左中右(⿲)结构、左部为「彳」、右部为「亍」的字符,并将其中部提取出来作为一个变量。然后,将其字形变换为全包围(⿴)结构、外部为「行」、内部为刚才那个变量的字形。」仿照这个例子,您就可以开始设计自己的变换器了。
值得注意的是,变换器不仅可以匹配简单的结构,还可以匹配复杂的结构树。例如,内置的一个规则是这样的:
 这表明变换器可以匹配任意层级的复合体结构,在编辑时点击「+」号可以将一个叶节点展开为新的子树,点击「−」号可以将子树改为一个叶节点。
这表明变换器可以匹配任意层级的复合体结构,在编辑时点击「+」号可以将一个叶节点展开为新的子树,点击「−」号可以将子树改为一个叶节点。
有的情况下我们想要使用的一个字根是系统的数据库中没有的,这时候我们就需要新建字符。
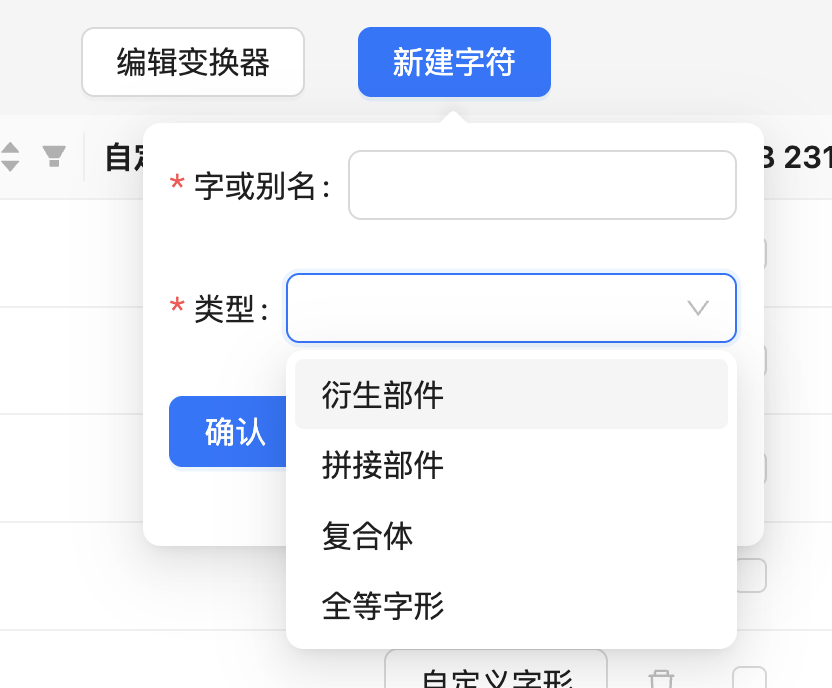 上图中,如果在「字或别名」中输入两个或以上的 Unicode 字符,则默认在私用区(U+F000 ~ U+F9FF)自动生成一个新的字符,其码位从 U+F000 开始依次递增;然后将输入的内容作为这个字符的别名。如果输入的是一个 Unicode 字符,则按其自身的码位加入。
上图中,如果在「字或别名」中输入两个或以上的 Unicode 字符,则默认在私用区(U+F000 ~ U+F9FF)自动生成一个新的字符,其码位从 U+F000 开始依次递增;然后将输入的内容作为这个字符的别名。如果输入的是一个 Unicode 字符,则按其自身的码位加入。
此外,在新建时需要同时提供一个字形的类别作为模板,可选的为衍生部件、拼接部件、复合体和全等字形。创建成功后该字符会根据这个类别来提供一个默认字形的模板,便于编辑。