配置拆分方式
如果您在元素界面定义了一些字根和笔画,则系统将尝试将汉字拆分为这些字根和笔画的组合。这里首先说明一下系统拆分的逻辑。
汉字的数量很多,有些在视觉上是一个不可分割的整体,有些则可以按自然间隙分成几块,而且后者占绝大多数,因为造字时大部分字是以形声、会意等方式组合起来的。因此,本系统已经将汉字按结构分解为了这些「块」,每块称为一个「部件」,而如果一个汉字不是部件,就称它为「复合体」。拆分时,首先用我们指定的字根来拆分部件,然后根据部件的拆分推导出复合体的拆分,层层推导直到覆盖所有汉字,这样可以大大提高拆分效率。
(如果您学过一些其他的形码方案,本系统中的「部件」类似于郑码中的「一般根」或者真码、张码中的「构件」概念。)
所以,拆分结果分两栏显示,一栏是部件的拆分,另一栏是从部件推导出的复合体的拆分。
系统拆分的具体结果取决于部件分析器、复合体分析器的类型,以及用户所指定的字根认同规则、拆分方式筛选规则。大部分顺序拆分的输入方案都只需要用到「默认部件分析器」和「默认复合体分析器」,因此我们将先以这两个为主讲解,后面再讨论其他情况。
默认字形分析算法简介
Section titled “默认字形分析算法简介”「默认部件分析器」的作用是将一个部件的所有笔画分为若干组,使得每一组要么恰好形成一个字根,要么为单个笔画。例如,部件「天」有可能分为「一」、「大」,也有可能分为「二」、「人」。针对每一个部件,默认部件分析器首先生成所有可能的这样分组的可能性,然后根据一定的规则筛选出最优的拆分方式,最终返回那个最优拆分方式对应的字根列表。
「默认复合体分析器」的作用是将一个复合体的所有部件的字根列表按顺序汇总起来,构成一个整体的字根列表。例如,复合体「拆」由「扌」、「斥」构成,其中「扌」本身是个字根,「斥」分为「斤」、「丶」两个字根,则将两者合并起来变成「扌」「斤」「丶」三个字根。
因此,默认字形分析算法可以保证对于每一个字,都能将其分析为若干个字根的列表。
下面将介绍默认默认字形分析算法所接受的一些配置参数。
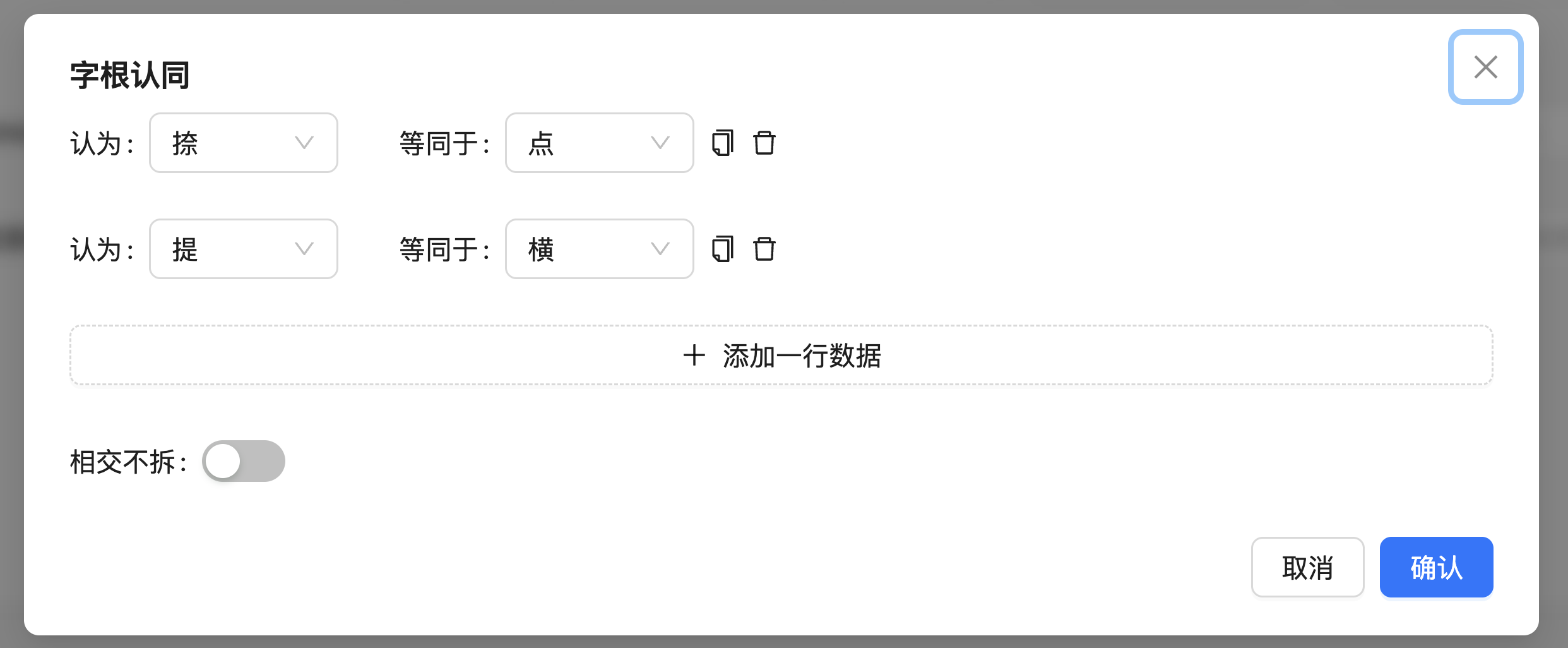
配置字根认同规则
Section titled “配置字根认同规则”「字根认同」是指判断某个字中是不是某个字根,以及两个字根是不是相同。本系统为了尽量兼容更多人的使用习惯,采取的是「能分尽分」的策略,所以对字根认同的要求会比一般的输入方案要严格一些,具体有以下规则:
- 只有字根中的笔画依次对应相同,才视为相同字根。如「少三」与「小」(一个是竖钩,一个是竖),「八」与「办无力」(一个是撇点,一个是点点)不作为相同字根处理
- 同时这意味着对笔顺敏感,如「力」与「为字框」、「化字边」与「龙下角」、「里无日」与「土」虽字形相同,仍作为不同字根处理;如方案不打算进行区分,需自行归并。
- 只有字根中的笔画的交、连、散关系相同,才视为相同字根。如「全字头」与「人」不作为相同字根处理。
我们可以在上面的字根认同规则的基础上做一些自定义。例如一般来说,虽然我们之前要求「只有字根中的笔画依次对应相同,才视为相同字根」,但是如果某个字根含有捺,那么把这个捺换成点之后的东西也认为是同一个字根(如木字旁和木),或者如果某个字根含有提,那么把这个提换成横之后的东西也认为是同一个字根(如足字旁中的止)。在「字根认同」中,可以按需要来合并不同笔画。
有些形码方案(如小鹤音形和二笔类)认为如果一个字根中的某些笔画与字根之外的其他笔画相交,就不再认为是这个字根。如果您的方案属于这一类,需要勾选「相交不拆」规则。
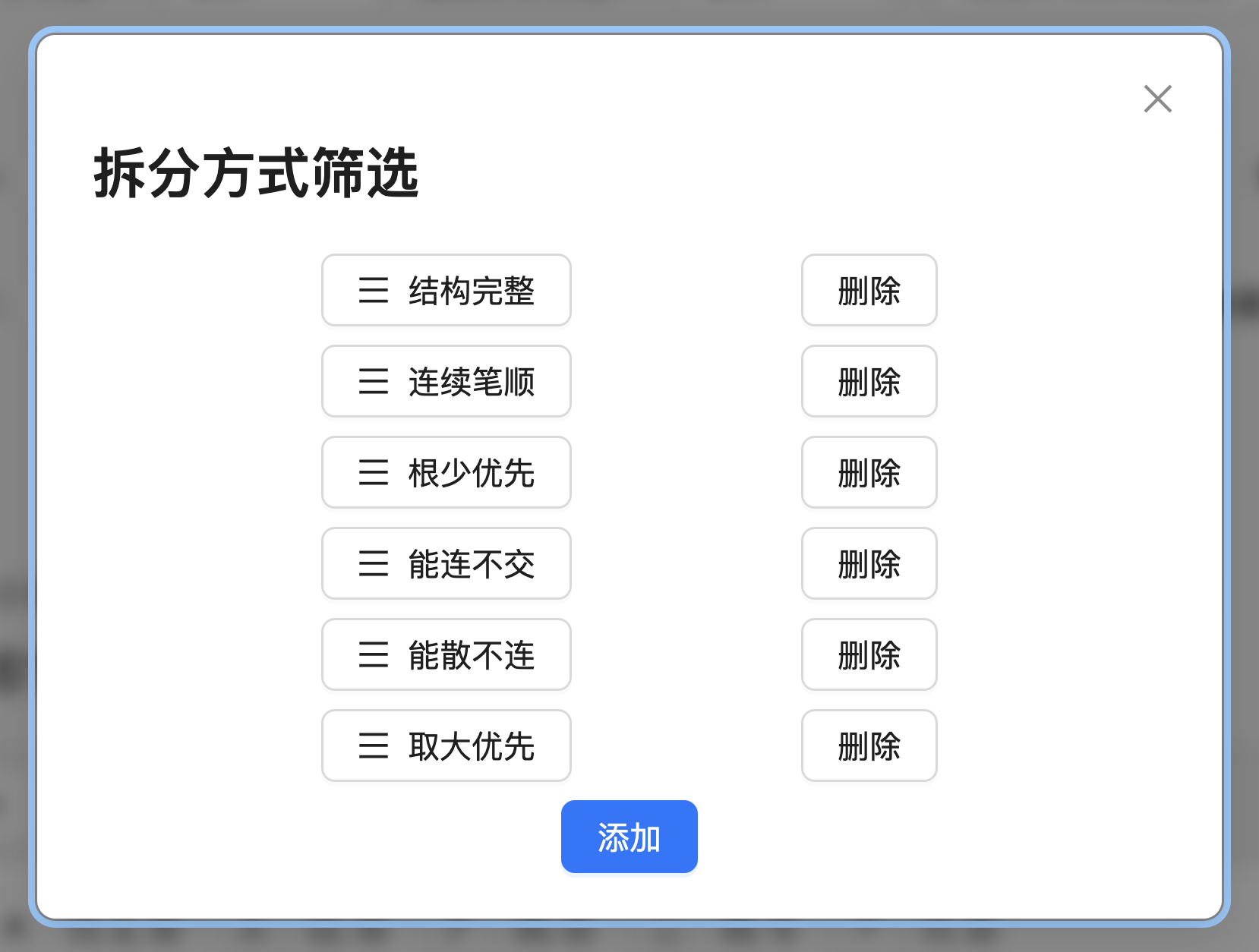
配置拆分方式筛选规则
Section titled “配置拆分方式筛选规则”「筛选规则」是指在部件的所有可能的拆分中,怎样选取一个最符合规则的拆分。系统内置了从以往的形码方案中收集来的规则,您可以添加一系列规则并且可以定义这些规则的优先级,当计算结果不符合预期时可以尝试调整优先级。
在右侧的结果中,展开一个字的拆分,会发现这些规则是如何用来拆字的。例如,筛选「天」这个字,可以注意到若干个规则依次执行,每一轮中只有该规则取得最优打分的拆分方式进入下一轮,直到只剩一个拆分方式:
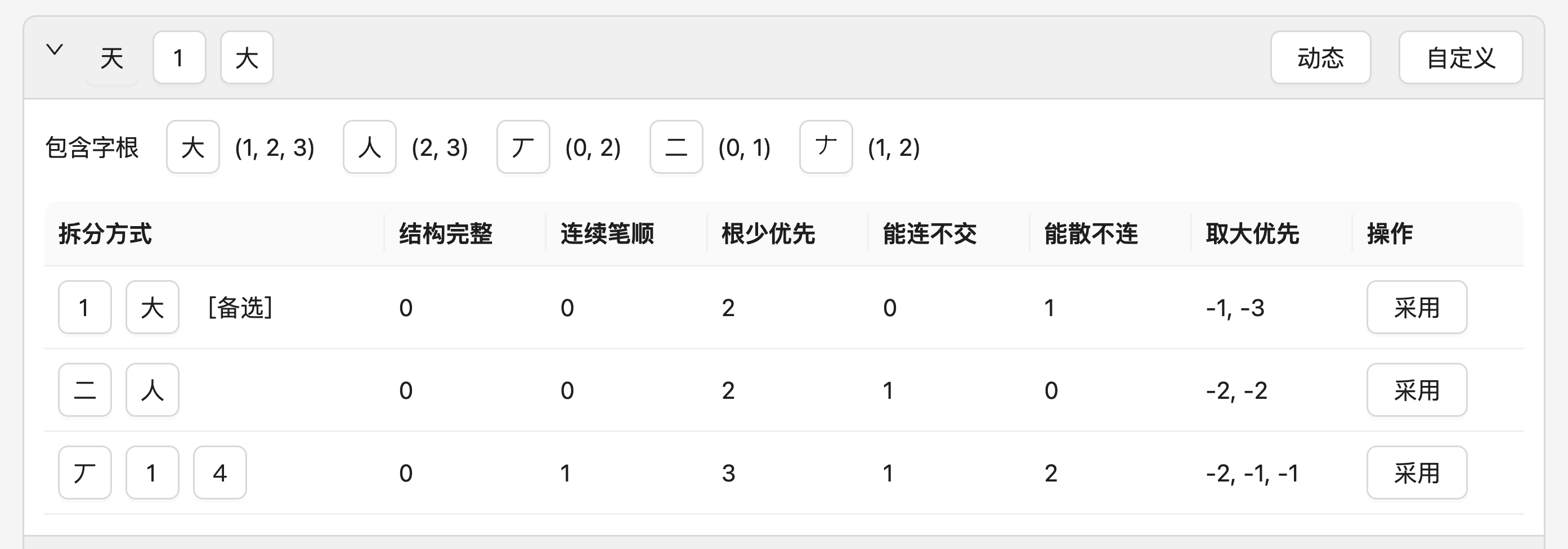
在这个「天」的拆分中:
- 因为有「连续笔顺」这条规则,所以「天 = 丆14」这种拆分方式就被过滤掉了;
- 而在下一步因为有「根少优先」这条规则,所以只有「1大」和「二人」两种拆分方式通过了筛选;
- 又因为「能连不交」,所以最终胜出的是「1大」这种拆分。
筛选规则一共有 12 个,详解如下。
- 结构完整,避免框类部件被拆散。
- 根少优先,筛选出拆分出字根数量最少的拆分方式。
- 全符笔顺,筛选出拆分完全符合笔顺的方式。
- 连续笔顺,筛选出拆分最符合笔顺的方式。
- 能散不连,筛选出字根之间相连次数最少的拆分方式。
- 能连不交,筛选出字根之间相交次数最少的拆分方式。
- 多强字根,尽量多使用强字根。强字根需自定义。
- 少弱字根,尽量少使用弱字根。弱字根需自定义。
- 非形近根,尽量少使用变形字根。变形字根需归并。
- 同向笔顺,让方向相同的笔画汇聚在同一个字根里。例:「兀」=「一」「儿」,「兰」=「丷」「三」。真码的拆分规则里有这一条。
- 取小优先,筛选出使拆分出的第一个字根笔画数量最少的拆分方式。如果有多个拆分方式中第一个字根笔画数量都一样多,那么就再看第二个,等等。
- 取大优先,筛选出使拆分出的第一个字根笔画数量最多的拆分方式。如果有多个拆分方式中第一个字根笔画数量都一样多,那么就再看第二个,等等。
以上规则可以在方案中自由添加,删除和排序,排序越靠前优先级越高。在分析结果中数字越小优先级越高,
配置自定义部件分析
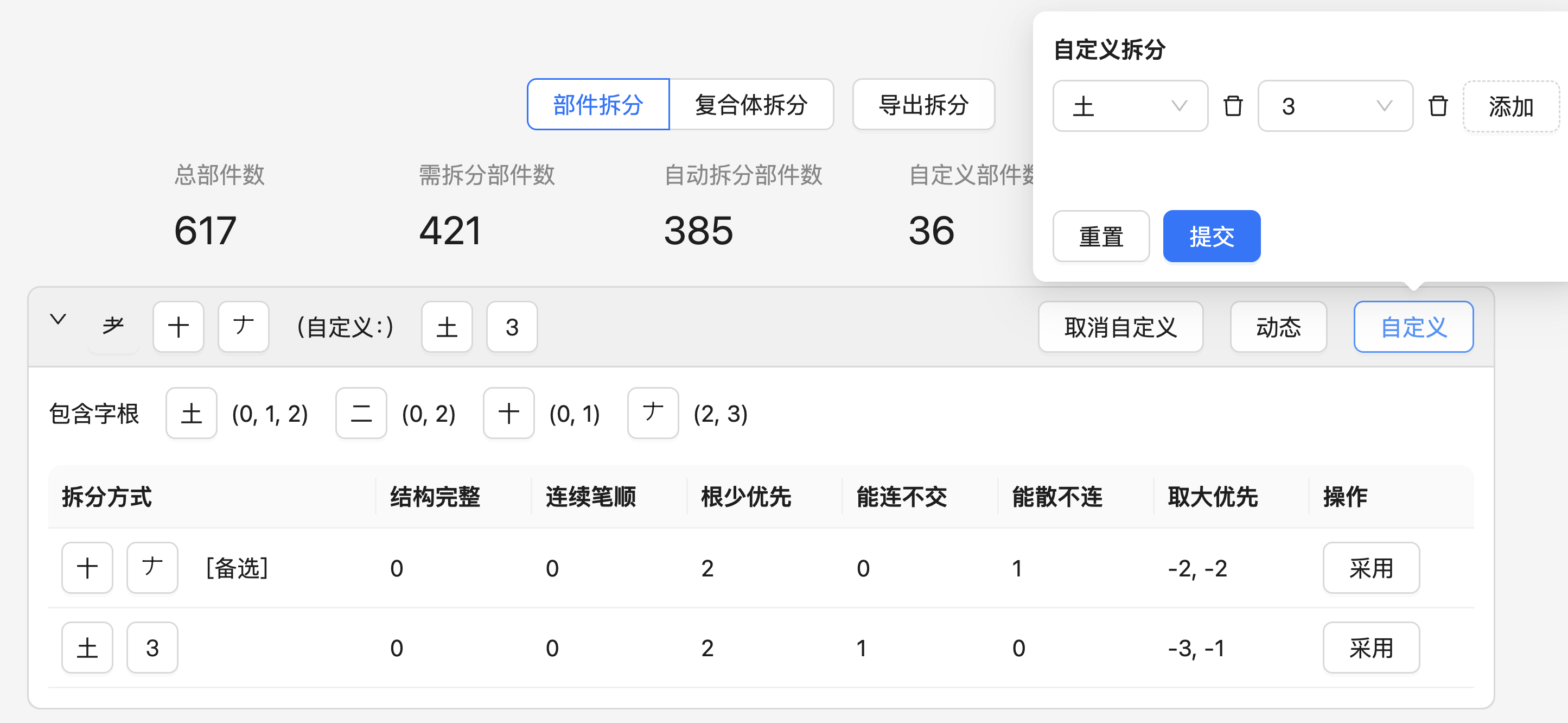
Section titled “配置自定义部件分析”因为汉字本身是千变万化的,部分的部件拆分结果无论怎么调整都有可能不合预期,或者就是单纯想添加无理拆分提高效率,这种情况下可以在相应拆分右侧添加自定义拆分。例如,「米十五笔」中将「耂」拆分为「土」、「丿」,但实际按规则应该拆为「十」、「𠂇」。
下一节中,我们将会定义编码规则,完成元素序列表和码表的生成。